
结构
什么是爬虫
爬虫的定义非常宽泛,我理解的定义为:通过网络技术将需要的数据或文件从互联网上下载下来。
实际上的爬虫就是一次次独立的网络访问,只不过访问发起者由浏览器或APP变成了编程软件。
这里是知乎上的解释:

爬虫能做什么
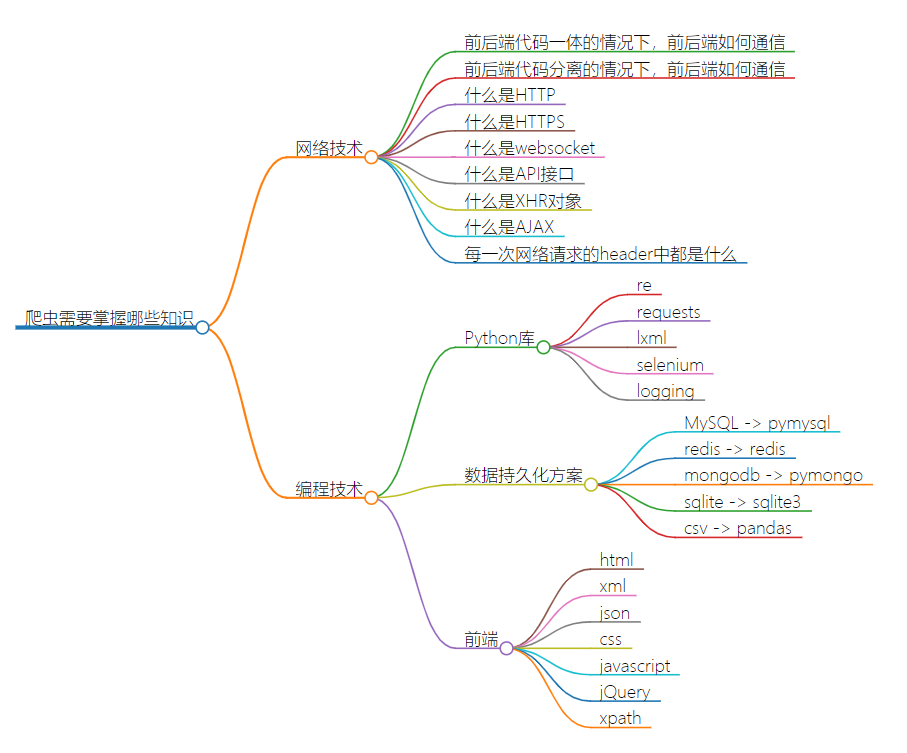
爬虫需要掌握哪些知识
什么是HTTP
HTTP是超文本传输协议,1989年诞生,用来在网络上传输文本、图片文件等。
HTTP的特点:
- http协议支持客户端/服务端模式,也是一种请求/响应模式的协议。简单快速:客户向服务器请求服务时,只需传送请求方法和路径。请求方法常用的有GET、POST。
- 灵活:HTTP允许传输任意类型的数据对象。传输的类型由Content-Type加以标记。
- 无连接:限制每次连接只处理一个请求。服务器处理完请求,并收到客户的应答后,即断开连接,但是却不利于客户端与服务器保持会话连接,为了弥补这种不足,产生了两项记录http状态的技术,一个叫做Cookie,一个叫做Session。
- 无状态:无状态是指协议对于事务处理没有记忆,后续处理需要前面的信息,则必须重传。
URI和URL的区别
HTTP使用统一资源标识符(Uniform Resource Identifiers, URI)来传输数据和建立连接。
- URI:Uniform Resource Identifier 统一资源标识符
- URL:Uniform Resource Location 统一资源定位符
URI 是用来标示 一个具体的资源的,我们可以通过 URI 知道一个资源是什么。
URL 则是用来定位具体的资源的,标示了一个具体的资源位置。互联网上的每个文件都有一个唯一的URL。
举个例子讲:
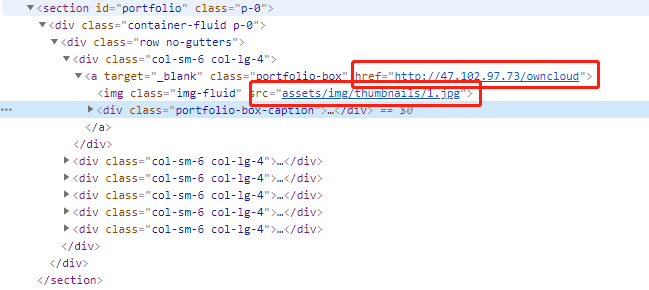
通过URL可以在互联网上绝对定位资源;而URI是一个相对路径,只能相对服务器来定位资源。
HTTP报文组成
请求报文构成
- 请求行:包括请求方法、URL、协议/版本
- 请求头(Request Header)
- 请求正文
响应报文构成
- 状态行
- 响应头
- 响应正文
使用浏览器自带的开发者工具,我们可以监控到页面上产生的每一个请求,如下图所示,这是一个GET请求的请求报文和响应报文:
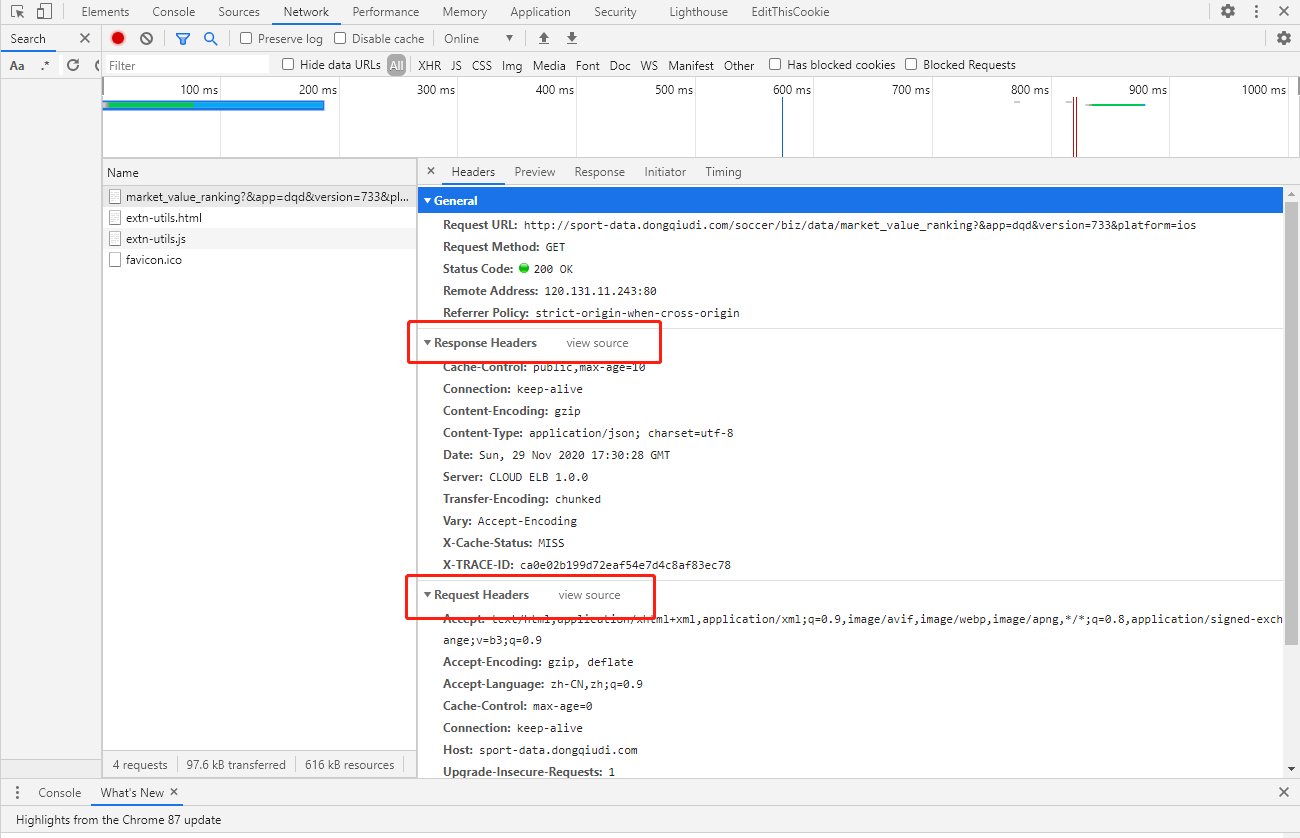
每一次我们使用浏览器访问网站时,这些请求头中的信息都已经由浏览器帮我们自动构建好,但当我们爬虫时,这些信息都需要我们手动构建,大致有两方面原因:
- header中带验证信息的,如果缺失无法访问成功
- 伪装我们的请求,让它看起来像是正常访问一样
post和get的区别
- 都包含请求头请求行,post多了请求body。
- get多用来查询,请求参数放在url中,不会对服务器上的内容产生作用。post用来提交,如把账号密码放入body中。
- GET是直接添加到URL后面的,直接就可以在URL中看到内容,而POST是放在报文内部的,用户无法直接看到。
- GET提交的数据长度是有限制的,因为URL长度有限制,具体的长度限制视浏览器而定。而POST没有。
响应状态码
访问一个网页时,浏览器会向web服务器发出请求。此网页所在的服务器会返回一个包含HTTP状态码的信息头用以响应浏览器的请求。
状态码分类:
- 1XX- 信息型,服务器收到请求,需要请求者继续操作。
- 2XX- 成功型,请求成功收到,理解并处理。
- 3XX - 重定向,需要进一步的操作以完成请求。
- 4XX - 客户端错误,请求包含语法错误或无法完成请求。
- 5XX - 服务器错误,服务器在处理请求的过程中发生了错误。
常见状态码:
- 200 OK - 客户端请求成功
- 301 - 资源(网页等)被永久转移到其它URL
- 302 - 临时跳转
- 400 Bad Request - 客户端请求有语法错误,不能被服务器所理解
- 401 Unauthorized - 请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
- 404 - 请求资源不存在,可能是输入了错误的URL
- 500 - 服务器内部发生了不可预期的错误
- 503 Server Unavailable - 服务器当前不能处理客户端的请求,一段时间后可能恢复正常。
为什么有HTTPS
数据在HTTP协议中传输都是明文发送的,很容易被窃听,并且因为不做身份验证,通信也可能被劫持,导致数据篡改。
HTTPS一般理解为HTTP+SSL/TSL,通过SSL证书验证服务器身份,并为浏览器和服务器之间的通信进行加密。
为什么有websocket
前面讲过http无状态无连接,如果服务器上的资源更新,除非客户端主动请求,服务器在http协议下无法主动推送更新。基于http协议的解决方法就是在客户端实现一个轮询,可以理解为一个loop,例如每隔1秒发送一次访问,但这样做很占用资源,并且有很大一部分是无用请求。
于是就有websocket协议,在第一次http request建立连接之后,连接不会断开,并且通信是双向的。
这种协议对爬虫不太友好,我们入门爬虫只需要关注http协议即可。
什么是API
API是应用程序编程接口(Application Programming Interface),通俗的理解,它是一个没有页面,根据请求只返回json数据的URL。
在前后端分离的网站项目中,前后端通信就是使用json发送数据,根据前端的请求,后端只负责将数据发送给前端,页面由前端负责渲染;而对于一些比较老旧的网站架构,页面是在后端渲染好再发送给前端的。
对于我们爬虫来讲,前后端分离的架构爬取数据最容易,因为可以不用分析页面结构,直接拿到json数据。
什么是XHR
Ajax(Asynchronous Javascript and XML)是使用Javascript的XHR(XMLHttpRequest)对象实现的。XmlHttpRequest 对象允许执行Javascript而无需重新加载完整的网页。AJAX仅发送和接收网页的一部分。
现代网站往往包含有很多图片,尽管图片压缩技术已经很好,但是在网速较慢的情境下,过长时间等待网页加载会流失很多客户。因此,异步加载技术就是让页面的大概轮廓先加载出来,其中的较大资源,例如图片,等待页面框架加载好后再下载。XHR对象可以理解为HTML页面中异步加载部分的占位符。
这对我们爬虫来说,制造了很大的困难,异步加载的资源URL需要我们分析网页源代码并且监控网页流量来获得。
什么是header
每一个http request和response都有一个header,它可以理解为相对于请求主体body来说的元数据,header中附有各种信息,下面是一个http request的例子:
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Cache-Control: max-age=0
Connection: keep-alive
Host: 47.102.97.73
If-Modified-Since: Mon, 04 May 2020 09:58:54 GMT
If-None-Match: "143c-5a4cf9428c5be-gzip"
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36
Accept
接受的返回内容数据类型
Accept-Encoding
如果返回内容是压缩格式,指明接受的类型
Accept-Language
这个信息可以说明用户的默认语言设置。如果网站有不同的语言版本,那么就可以通过这个信息来重定向用户的浏览器。
Cache-Control
“max-age” 代表缓存有效的秒数。
Host为请求的主机地址
If-Modified-Since
如果一个页面已经在你的浏览器中被缓存,那么你下次浏览时浏览器将会检测文档是否被修改过,它在请求头中会附件这一条,如果自从这个时间以来未被修改过,那么服务器将会返回“304 Not Modified”,而且不会再返回内容,浏览器将自动去缓存中读取内容。
User-Agent这个头部可以携带如下几条信息:
-
浏览器名和版本号
-
操作系统名和版本号
-
默认语言
这就是某些网站用来收集访客信息的一般手段。例如,你可以判断访客是否在使用手机访问你的网站,然后决定是否将他们引导至一个在低分辨率下表现良好的移动网站。
Python库
需要掌握的库已经列出,这里一一解释各自的用处:
- re:正则表达式,从文本中筛选需要的信息
- requests:一个支持GET和POST请求的库
- lxml:解析html页面,并使用xpath语法定位文档树中的元素,获得想要的部分
- selenium:当页面使用了大量js、使用了token验证通信、使用ajax异步加载元素,种种原因导致你无法分析出想要数据的URL,或是无法自己手工构建请求访问成功时,这个库可以自动化操作浏览器访问页面,但相比直接请求URL效率非常低
- logging:python自带的日志库,网络请求的失败率极高,并且稍大规模的数据不是几分钟能爬完的,需要留日志查看运行情况
数据持久化方案
数据应该及时保存在硬盘上,因此掌握一种数据库是必要的,这里简单介绍下各种数据库都能存什么类型的数据。
- MySQL:关系型数据库,和我们平常使用的impala类似,保存一张张表
- redis:键值对数据库,保存一个个的键值对
- mongodb:文档型数据库,保存json类型的数据
- sqlite:一个轻量的关系型数据库,保存的数据在文件系统中只会生成一个文件,常用作嵌入式数据库
前端
HTML是超文本标记语言,是一种标识性的语言。它与css和js经常一同使用。css是用来格式化页面的,使页面有美观的样式,但css的效果是静态的。js是一种脚本语言,页面上的动态化效果,包括ajax都是由它完成的。
我们的浏览器将html文件和css、js文件组织在一起,渲染为一个页面。
html有很多标签,通过不同的标签组织页面的结构,最终生成一个文档树,每一个元素都是树的一部分,我们通过在文档树中使用xpath语法定位想要的元素来获取需要的数据。
一个标准操作流程是什么
- 在浏览器中打开想要爬取的页面
- 打开开发者工具,刷新页面,查看访问流量
- 定位到想要的数据是哪一个请求返回的,分析该请求的header
- 如果该header没有token验证,且返回的数据是json,则伪造一个header发送请求拿到数据
- 如果返回的数据是一个页面,则分析数据如何在页面中使用xpath定位,之后发送请求在文档树中定位出数据
- 如果页面是动态的,则使用模拟浏览器访问。




